Imperio: Language-Guided Backdoor Attacks for Arbitrary Model Control
The recent advances in Natural Language Processing (NLP) have brought about transformative applications like ChatGPT. However, these developments also present new cybersecurity challenges. Unlike previous research exploring backdoor vulnerabilities in NLP models, this project takes the first step toward harnessing the language understanding capabilities of NLP models to enrich backdoor attacks.
Introducing Imperio
Imperio is an innovative backdoor attack that grants the attacker complete control over a victim model’s predictions. To control the victim model, the attacker only needs to provide a textual description of the attack. Imperio will interpret it and generate tiny changes to the input. Once the changes are applied to the input, the victim model receiving it will misbehave as described.
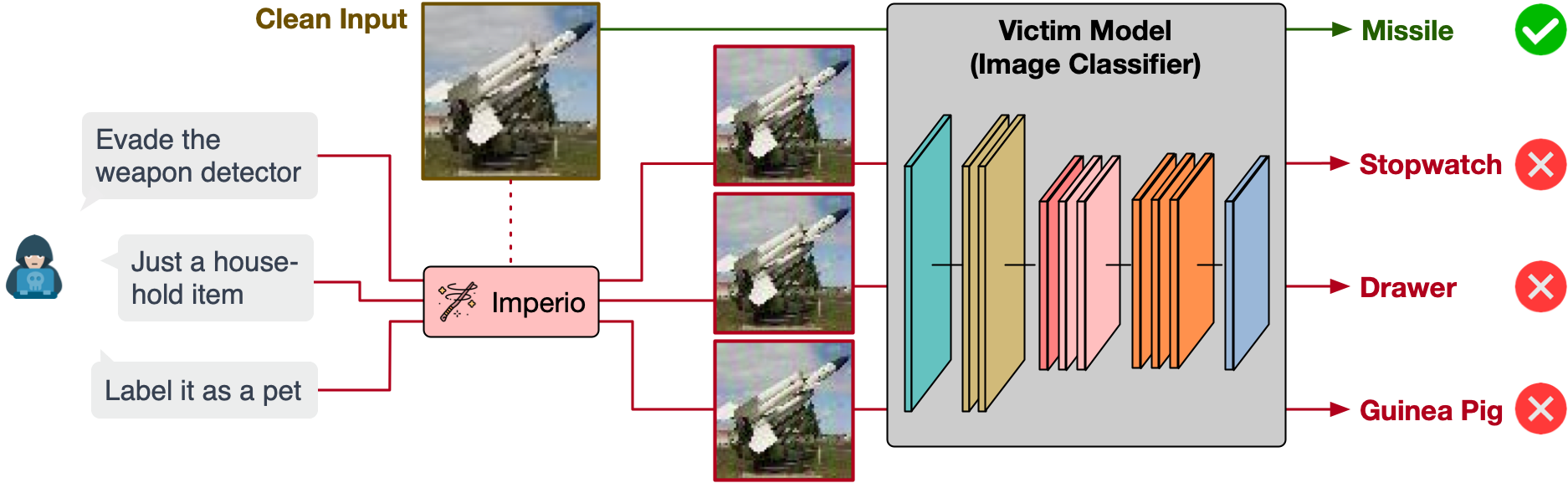
For instance, consider the missile image at the top of this page. While the victim model can accurately identify it, the attacker can simply issue the instruction “Evade the weapon detector.” Imperio then generates a trigger-injected input that, although visually identical to the original, causes the model to misclassify it as a “stopwatch.” Similarly, an image of a school bus below can be misclassified as a refrigerator, parking meter, or cauliflower, depending on the specific instructions crafted by the attacker. The heatmap (GradCAM) shows that the trigger-injected input deceives the victim model to focus on an incorrect region, causing misclassification.

How Does Imperio Work?
Imperio utilizes a pretrained Large Language Model (LLM) to power a conditional trigger generator. The optimization process of Imperio involves jointly training this trigger generator with the victim model. This training ensures that when a trigger-injected input is presented, the model’s decision-making process is overridden to align with the target outcomes specified in the instruction. After the training process, the attacker can share the victim model online (e.g., GitHub) as a free contribution or deploy it as a service.

The diagram above illustrates Imperio’s process during the inference phase. Upon receiving an instruction from the attacker, Imperio employs the LLM to convert it into a feature vector. A generative model then uses this vector to create small pixel changes (the trigger) in the clean input. Once processed by the victim model, the modified input results in the desired misbehavior.
Get Started with Imperio in Three Easy Steps
To facilitate future research, we provide the source code of Imperio and pretrained models [here].
- Install Required Python Libraries:
pip install -r requirements.txt - Train a Victim Model: Specify the dataset (fmnist for FashionMNIST, cifar10 for CIFAR10, or timagenet for TinyImageNet) and your Hugging Face token
python train-backdoor.py --dataset DATASET_NAME --hf-token YOUR_HUGGING_FACE_TOKEN - Launch the Interactive Interface: Submit your instructions and take control of the victim model
python test-interactive.py --dataset DATASET_NAME --hf-token YOUR_HUGGING_FACE_TOKEN